

Amazon RDS is a managed relational database service that lets you easily deploy, scale, and replicate databases. You can…

Andre Newman
Technical Writer

This is the first post in a three-part series on High Severity Incident (SEV) Management Programs. Check out part 2, Understanding The Role Of The Incident Manager On-Call (IMOC), and part 3, Understanding The Role Of The Technical Lead On-Call (TLOC).
High severity incident management is the practice of recording, triaging, tracking, and assigning business value to problems that impact critical systems. The purpose of establishing a program is to enhance the customer experience by improving your infrastructure reliability and upskilling your team. In this guide, we will share how to establish and measure the success of your own high severity incident management program.
The management of high severity incidents encompasses high severity incident (SEV) detection, diagnosis, mitigation, prevention, and closure. SEV prevention includes SEV review and SEV correlation.
SEV is a term used to refer to an incident, it is derived from the word severity.
SEVs are common across all industries. They impact our ability to catch flights, access our bank accounts, buy the latest game we are excited about and much more.
The following are examples of SEVs that have occurred:
More examples have been collected and shared by Outage Report.
SEV levels are designed to be simple for everyone to quickly understand the amount of urgency required in a situation. Launching your high severity program with SEV levels is important because it will make it easier to inform everyone across your engineering team how you classify incidents.
SEV levels empower and educate your entire team to feel confident lodging SEVs and effectively prioritising them.
An example of SEV levels are described in the table below:
| SEV Level | Description | Target resolution time | Who is notified |
|---|---|---|---|
| SEV 0 | Catastrophic Service Impact | Resolve within 15 min | Entire company |
| SEV 1 | Critical Service Impact | Resolve within 8 hours | Teams working on SEV & CTO |
| SEV 2 | High Service Impact | Resolve within 24 hours | Teams working on SEV |
There are three service level terms often used to measure the level of service that will be provided to customers. These terms are; service level indicators (SLIs), service level objectives (SLOs) and service level agreements (SLAs). Companies will often set an SLO which is higher than their SLA, for example the SLA provided to customers would be 99.99% but the internal unpublished SLO would be 99.999%.
An SLA level of 99.99 % uptime/availability gives the following periods of potential downtime/unavailability:
You can calculate the error budget you have available based on your SLO and SLA at uptime.is.
The full lifecycle of a SEV involves detection, diagnosis, mitigation, prevention and closure. There is a glossary of SEV terms just below.
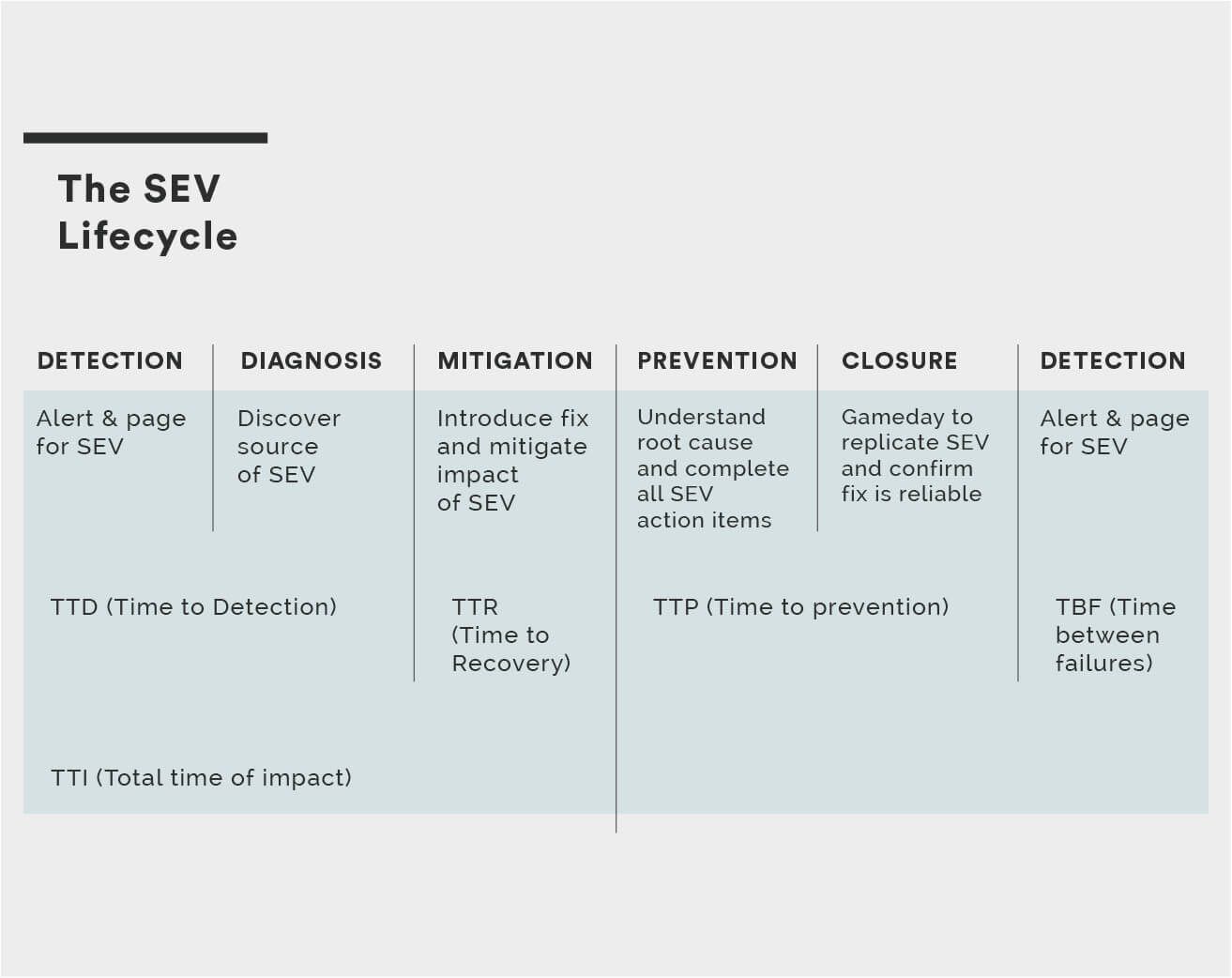
When we are reporting on SEVs that have occurred in the past to look for trends and patterns, it is useful to understand the overall mean measurements for SEVs. For example, the mean time to detection (MTTD) for all SEVs. This measurement is useful to dive deeper and understand which types of systems or services take much longer to detect incidents for. Engineers will often take the time to tag incidents because it enables the creation of visualizations by cause and magnitude.
High Severity Incidents (SEVs) are measured by the availability error rate and total time of impact. We use the formula below to identify the number of customer requests which were impacted:
% loss * outage duration
This also lends itself to prioritization. For example, you can assign a value to each customer request and the result will be visibility of the most important requests. You may choose to assign a higher value to requests related to new product launches, e.g. the launch of a new TV series that is being streamed.
Revenue impact for Freemium products can occur due to outages impacting customer upgrade flows. For example, a Freemium photo storage service’s revenue could be impacted by a mail campaign outage. This could then result in campaign mail not sending when a user hits their storage quota and is prompted to upgrade.
The following acronyms are used to measure and track SEVs. This data is important to collect in your SEV tracking tool. It is best to fill in all data when the SEV has been resolved. When you store this data it can then be used to automatically generate monthly SEV metrics reports.
| SEV Term | Description |
|---|---|
| TTI | Total time of impact |
| TTD | Time to detection |
| TTE | Time to engagement |
| TTR | Time to resolution |
| TTP | Time to prevention |
| TBF | Time between failures |
When you are establishing your high severity incident management program it is important to consider the pricing model of your product. If your product pricing uses a freemium model you likely have different SEV levels than a product with subscription pricing and no free tier.
If your product has tiers such as business and enterprise with different costs you could classify requests for these products with different severity ratings. This is very useful if you have VIP customers who require higher levels of availability than the majority of your customers.
Any SEV which involves loss of customer data should be classified as a SEV 0.
| SEV Level | Data Loss Impact |
|---|---|
| SEV 0 | Loss of customer data |
| SEV 1 | Loss of primary backup |
| SEV 2 | Loss of secondary backup |
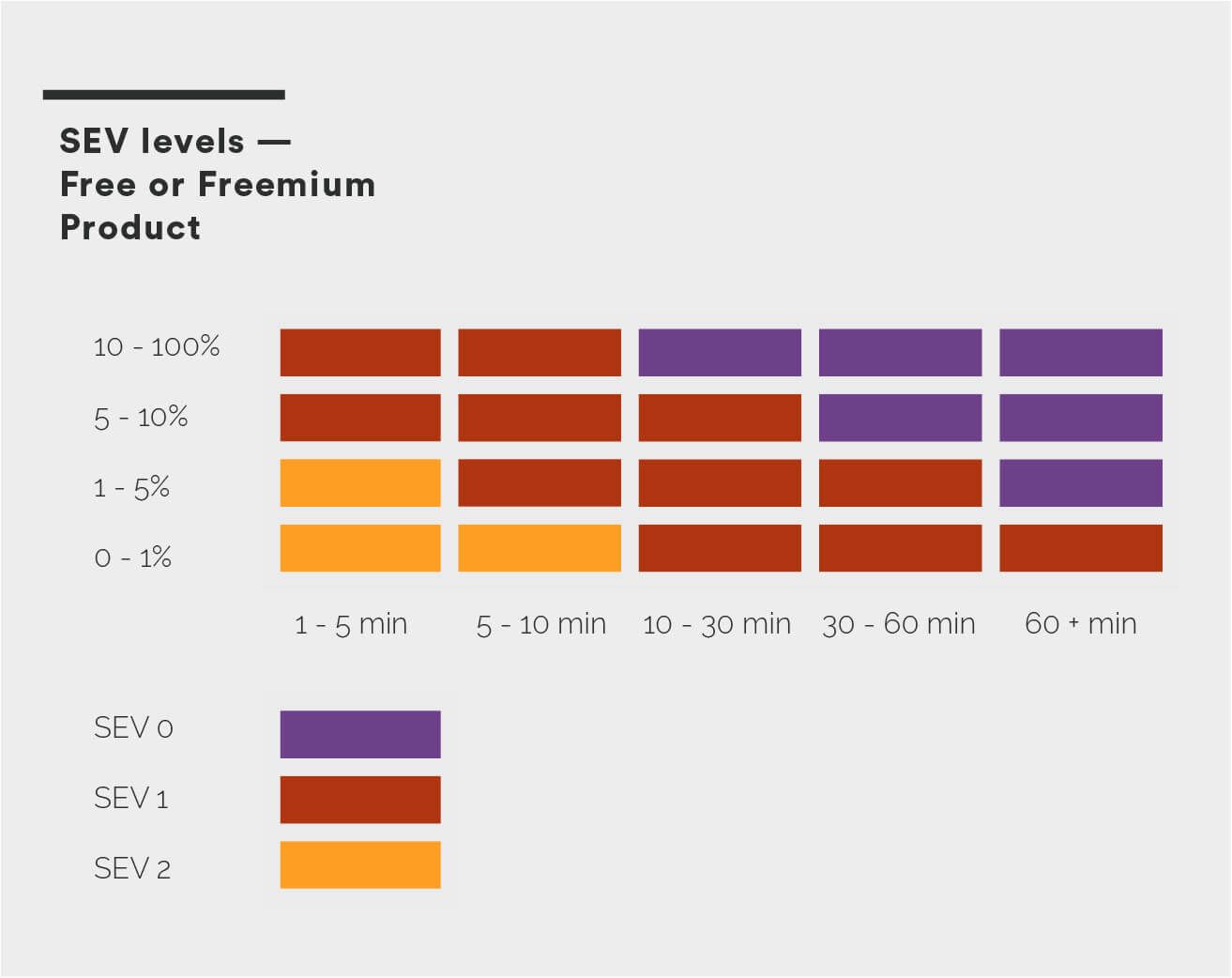
The following diagram illustrates the way to measure SEV levels for a free or freemium product. For example, a 90% loss of customer requests * 10min is classified as a SEV 1 incident. This is considered a critical service impact but we do not classify it as catastrophic because of the length of the outage and insignificant impact on revenue.
The diagram below demonstrates a SEV 1 impacting WWW and API with no impact to client. This is classified as a critical service impact. We measure this SEV as 0.2% * 30 min (6) for WWW and 0.11% * 30 min (3.3) for API. The 99.99 SLA has been breached. In the example below the SLA is 99.99 for availability.

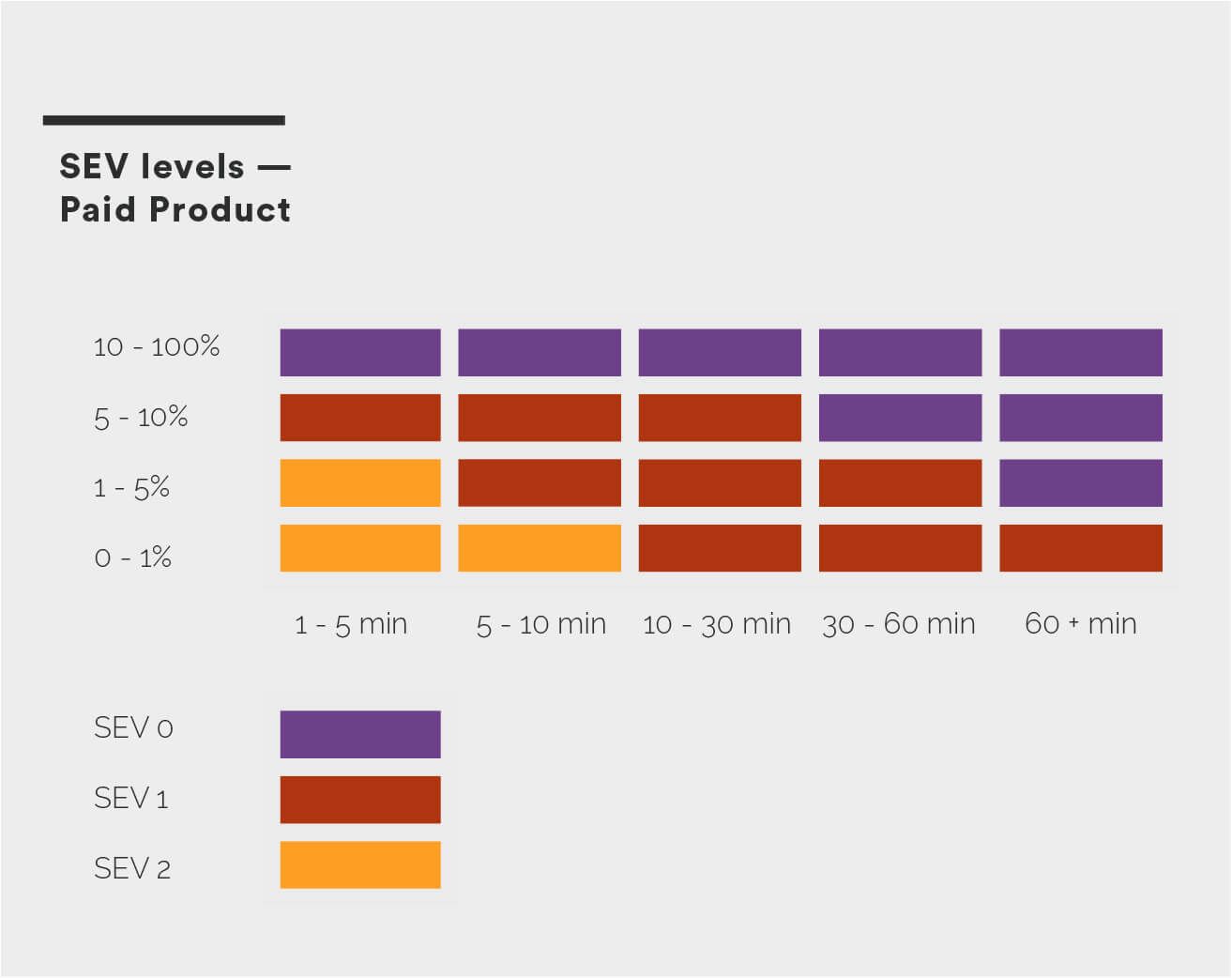
The following diagram illustrates the way to measure SEV levels for a product with subscription pricing. For example, a 90% loss of customer requests * 10min is classified as a SEV 0 incident. This is considered a catastrophic service impact due to the impact to revenue.
There are two roles which are important to establish when you create your high severity incident management program. These are critical to ensure your team can effectively diagnose, mitigate and prevent SEV 0s. These roles are the Incident Manager On-Call (IMOC) and the Tech Lead On-Call (TLOC).
How do you set up IMOCs for success during SEV 0s?
IMOCs play a critical role in managing SEV 0s. It is important to train IMOCs before they do their first rotation because they are the sole person responsible for coordination and communication of the SEV 0 with the entire company.
IMOC training is best conducted in a one hour face-to-face training session with time for questions. It involves gaining an understanding of the following:
To ensure IMOCs can be as effective as possible, the following practices should be in place:
When your IMOC is paged, the first thing they will need to do is look at the recorded SEV details and then open the Critical Services Dashboard. Next we will discuss how to categorize SEVs to enable the IMOC to quickly grok the impact of SEVs.
When establishing your high severity incident management program it is useful to be able to view requests split by different categories such as services or new products. For example, if your team is responsible for a website, API and desktop client, being able to determine the impact based on the requests for WWW, API and Client will be very useful. This will enable you to more quickly work through the full SEV lifecycle.
The dashboard below is an example of how your dashboard would appear during a SEV impacting WWW and API with no impact to Client. There is also a red line to assist in determining if the SLA has been breached. In the example below the SLA is 99.99 for availability.
There is a significant benefit to enabling and empowering everyone in your company to have the understanding and confidence to record SEVs.
At the Toyota Motor Manufacturing plant in Kentucky they “pull the Andon cord” 5000 times per day. The Andon cord is a physical rope that follows the assembly line; it can be pulled at any time to stop the manufacturing line. When someone pulls the cord and the problem is serious enough, everyone stops what they’re doing until the problem is fixed.
To empower your team, set up tooling and automation to make it simple for everyone to record, discuss, recall, and correlate SEVs. Many teams are now distributed around the world with multiple offices. Giving your team an easy to use web-based tool to record SEVs will increase the likelihood your high severity incident management program will be successful.
We have created a simple Google Form for you to use with your engineering teams. This form will enable all engineers to lodge SEVs. You can create a copy of this RecordSEV tool Google Form. The RecordSEV tool can be seen below:

To enable effective recall of SEVs and facilitate discussions it is useful to give SEVs descriptive names. A name generator that enables you to match a descriptive word and animal can be used to choose a name for the SEV. For example, “SEV 0 Cheeky Kangaroo”.
Descriptive SEV names will improve communication for your SEV program. Alternatively, SEVs can be named using numerical codes or timestamps.
From industry analysis of SEVs we can classify the causes of SEVs as either technical issues or cultural issues. Some SEVs are caused by both technical and cultural issues. See the table below for examples:
| Type of Issue | Example |
|---|---|
| Technical Issue | Incorrect configuration change |
| Cultural Issue | Lack of on-call training |
Technical Issues
Cultural Issues
How do you prevent SEVs from repeating?
It is possible to prevent SEVs from occurring again but to do this you must be able to record, correlate, and track SEVs.
We recommend making sure you have the following in place:
Chaos Engineering is the facilitation of controlled experiments to uncover weaknesses of your infrastructure and team. Having your entire engineering team routinely performing chaos experiments on your systems will help you identify problems before they become incidents, and along the way increase your confidence that your systems and teams can handle failure. When used alongside the prevention methods described above, chaos empowers your teams to proactively uncover the technical and cultural issues that impact your company.
Here is a list of resources you can use to further explore how Chaos Engineering can be reduced to reduce the severity and number of incidents at your company:
A high severity incident management program is an important subset of reliability engineering, focused on ensuring that a team is prepared to manage incidents. This might seem complex; however, it can greatly improve your customer experience and empower you to meet SLAs. This will also empower you to be better prepared for compliance and auditing events as they arise. By following this guide you will be able to establish your own high severity incident management program and measure its success.
Join the Chaos Engineering Slack to connect with 5,000+ SREs and engineers about establishing SLOs and reducing incidents.

Gremlin empowers you to proactively root out failure before it causes downtime. See how you can harness chaos to build resilient systems by requesting a demo of Gremlin.
Get started